A new evaluation framework that captures what actually matters in real conversations—structure, intent, and paralinguistic cues
For years, Word Error Rate (WER) has been the default metric for evaluating Automatic Speech Recognition (ASR). It’s simple, well-understood, and useful for comparing vendors. Many ASR decisions—even large enterprise deals—still hinge on tiny differences in WER scores.
But as voice agents move into real-world phone workflows, WER increasingly falls short. It captures only a narrow slice of accuracy and misses the conversational cues that determine whether a transcript is actually useful.
Below, we break down what WER measures, why it’s limited, and introduce a more complete evaluation framework designed for modern conversational AI systems.
WER compares a model’s transcript to a human reference transcript and counts three types of edits:
Substitutions — wrong words
Insertions — extra words
Deletions — missing words
These errors are divided by the number of words in the reference:
WER = (S + I + D) ÷ total reference words
WER’s value comes from its simplicity. It’s consistent, replicable, and easy to benchmark across models, datasets, and vendors.
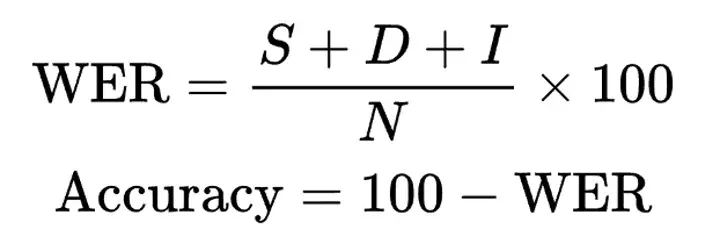
Calculating WER starts by aligning the ASR output with the ground-truth transcript.
The algorithm minimizes the Levenshtein edit distance—the smallest number of substitutions, insertions, and deletions needed to transform one string into the other.
Once aligned, the number of edits is divided by the number of words in the reference transcript. A perfect transcription has a WER of 0, which is the ideal engineers aim for when optimizing ASR systems.
Despite its usefulness, WER falls short in real conversational settings. Here’s why:
1. It treats all mistakes as equal
A missed filler like “you know”, a harmless spelling change (“thirty” vs. “30”), or a formatting variation all worsen the score—even if the meaning stays the same.
Meanwhile, mishearing “approved” as “declined” carries the same penalty, even though the impact is dramatically different.
2. It ignores who is speaking
If Speaker A’s words are attributed to Speaker B, the conversational logic collapses.
For analytics, QA, or LLM reasoning, the transcript becomes essentially unusable.
3. It doesn’t capture timing, pauses, or boundaries
Cut sentences, merged thoughts, or missing long pauses disrupt conversational flow—crucial for intent, sentiment, and turn-taking.
4. It misses human behaviors entirely
Laughter, breaths, hesitations, coughs, stutters—all carry emotional or contextual meaning.
WER ignores these cues completely.
Two models with similar WER can perform very differently once deployed.
Because of this, WER should be treated as one metric—not the metric—for evaluating ASR or voice-agent accuracy.
To evaluate speech-to-text performance realistically, we use a weighted scoring framework that reflects the elements of human conversation that matter most.

To evaluate speech-to-text performance realistically, we use a weighted scoring framework that reflects the elements of human conversation that matter most.
Transcript accuracy (WER)
Measures correctness of words—but says little about conversational structure.
Speaker diarization
Evaluates whether each word is attributed to the correct speaker, whether turn boundaries are natural, and whether each participant’s identity stays consistent.
Failures here break the entire conversational logic.
Paralinguistic event recognition
Captures non-speech cues like laughter, breaths, coughing, and pauses—signals that reveal emotional context and state changes.
Filled pause identification
Handles “um,” “uh,” and similar markers of hesitation or uncertainty.
Missing or hallucinating these alters speaker intent.
Disfluency Recognition
Identifies stutters, partial-word repeats, and mid-sentence corrections.These provide insight into emphasis, uncertainty, or self-correction.
Together, these components produce a richer, more conversation-aware assessment of SST quality—reflecting not only what was said but how the interaction unfolded.
Note: Punctuation affects tone and meaning, but consistent scoring is difficult, so it’s excluded from the leaderboard.
A truly accurate SST system must capture the full structure and behavior of a conversation so an LLM can reconstruct the interaction from text alone.
Speaker diarization
LLMs build reasoning around who is speaking.
Misattributed speakers or broken turns destroy context and coherence.
Paralinguistic cues
Laughter, breaths, and pauses reveal hesitation, relief, tension, or unfinished thoughts—essential cues for understanding intent and emotional state.
Filled pauses
Signal uncertainty or thinking time, guiding whether an agent should respond immediately or wait.
Disfluencies
Reflect corrections, emphasis, or difficulty articulating a point.Capturing these details enables the LLM to recreate:
• pacing
• turn-taking
• hesitation
• certainty
• intent
• conversational flow
This results in outputs that reflect the real interaction, not a flattened approximation stripped of human nuance.
A truly accurate SST system must capture the full structure and behavior of a conversation so an LLM can reconstruct the interaction from text alone.
Speaker diarization
LLMs build reasoning around who is speaking.
Misattributed speakers or broken turns destroy context and coherence.
Paralinguistic cues
Laughter, breaths, and pauses reveal hesitation, relief, tension, or unfinished thoughts—essential cues for understanding intent and emotional state.
Filled pauses
Signal uncertainty or thinking time, guiding whether an agent should respond immediately or wait.
Disfluencies
Reflect corrections, emphasis, or difficulty articulating a point.Capturing these details enables the LLM to recreate:
• pacing
• turn-taking
• hesitation
• certainty
• intent
• conversational flow
This results in outputs that reflect the real interaction, not a flattened approximation stripped of human nuance.
.png)
Methodology & Updates
This leaderboard is based on manual annotation of real-world audio files. Each file reflects a different context and speaking environment — including noisy phone lines, fast talkers, accents, interruptions, and multi-speaker turn-taking.
Our team reviewed transcripts word-by-word and turn-by-turn to evaluate not just Word Error Rate, but structural comprehension and paralinguistic cues that matter in real conversations.
We refresh the dataset and update the leaderboard regularly to ensure the results stay representative and current.
Join leading enterprises using AveraLabs to deliver human-level service at AI speed
© 2025 AveraLabs

.png)